(1)本文及后续文章均使用IDA Pro 9+进行软件逆向,IDA Pro 9之前版本的静态栈视图可能与文中截图有略微差别,但不影响分析使用。如需安装IDA Pro 9.1,可参考前面的文章。
(2)程序中绘制的栈布局图片使用draw.io软件完成。
(3)学习之前需要掌握C语言的基础知识,可参考前面的C语言系列文章。
(5)PWN环境的搭建、逆向基础知识等内容本系列文章进行了省略,可自行从网上其他地方学习获得。
(6)本文附件地址(“基础知识”文件夹)。
一、GCC 编译参数
1、查看默认的gcc编译参数:
|
|
2、编译生成32位的程序
|
|
3、有关Canary保护的选项
|
|
4、有关NX保护(No-eXecute)(DEP)的选项
|
|
5、有关PIE的选项
|
|
6、有关RELRO(ReLocation Read-Only)的选项
|
|
二、x86 程序栈布局
如果看下面的内容读完后还是不理解的话,建议学习“轩辕的编程宇宙”公众号的课程《从零开始学逆向》第7课:函数调用过程汇编分析。
其他的一些前置知识学习,可以参考本博客“About”中介绍的学习路径填补基础知识。
1、函数调用栈
函数调用经常是嵌套的,在同一时刻,堆栈中会有多个函数的信息。每个未完成运行的函数占用一个独立的连续区域,称作栈帧(Stack Frame)。栈帧是堆栈的逻辑片段,当调用函数时逻辑栈帧被压入堆栈, 当函数返回时逻辑栈帧被从堆栈中弹出。栈帧存放着函数参数,局部变量及恢复前一栈帧所需要的数据等。
编译器利用栈帧,使得函数参数和函数中局部变量的分配与释放对程序员透明。编译器将控制权移交函数本身之前,插入特定代码将函数参数压入栈帧中,并分配足够的内存空间用于存放函数中的局部变量。使用栈帧的一个好处是使得递归变为可能,因为对函数的每次递归调用,都会分配给该函数一个新的栈帧,这样就巧妙地隔离当前调用与上次调用。
栈帧的边界由栈帧基地址指针EBP和堆栈指针ESP界定(指针存放在相应寄存器中)。EBP指向当前栈帧底部(高地址),在当前栈帧内位置固定;ESP指向当前栈帧顶部(低地址),当程序执行时ESP会随着数据的入栈和出栈而移动。因此函数中对大部分数据的访问都基于EBP进行。
更具描述性,以下称EBP为帧基指针, ESP为栈顶指针,并在引用汇编代码时分别记为%ebp和%esp。
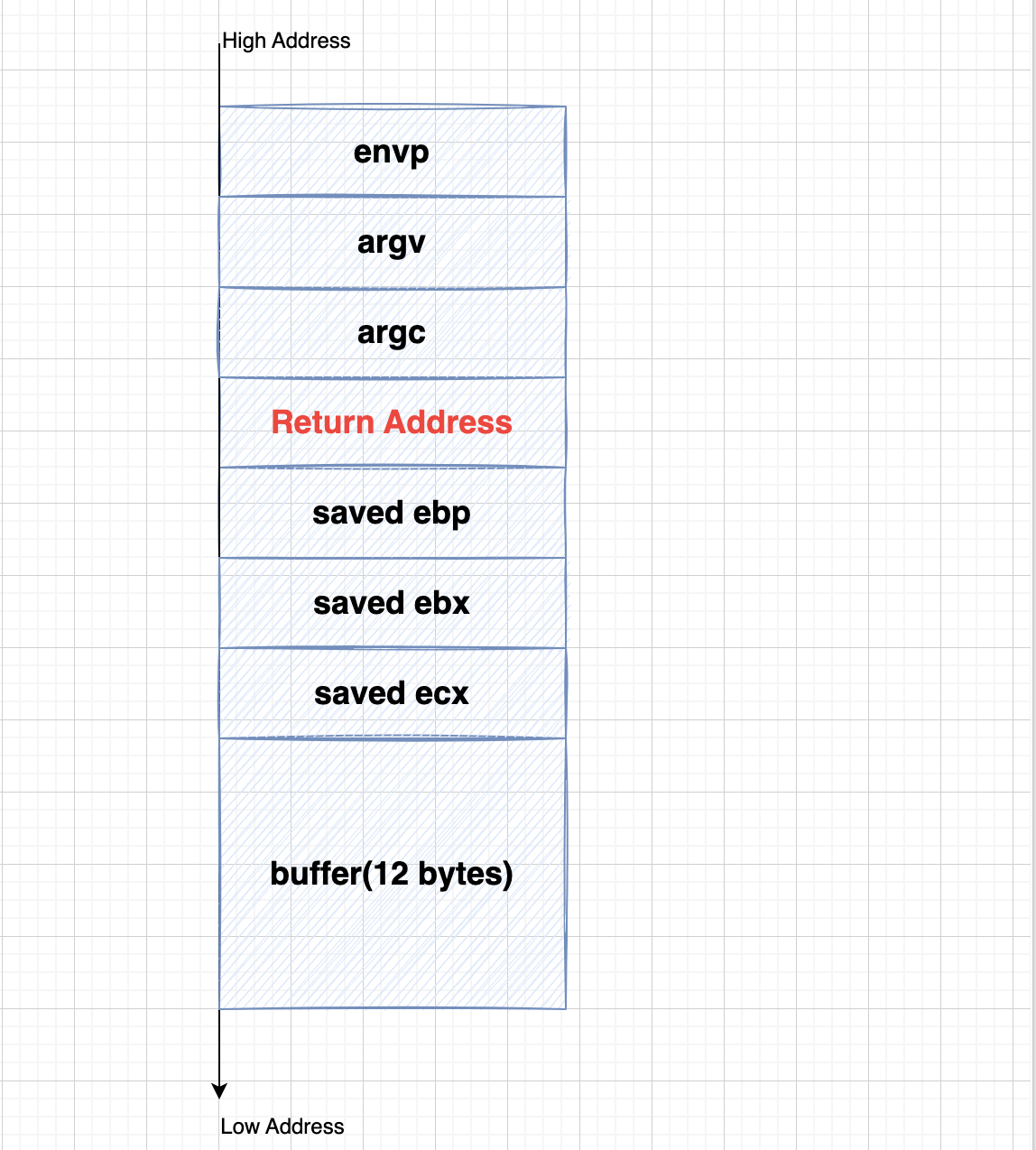
函数调用栈的典型内存布局如下:
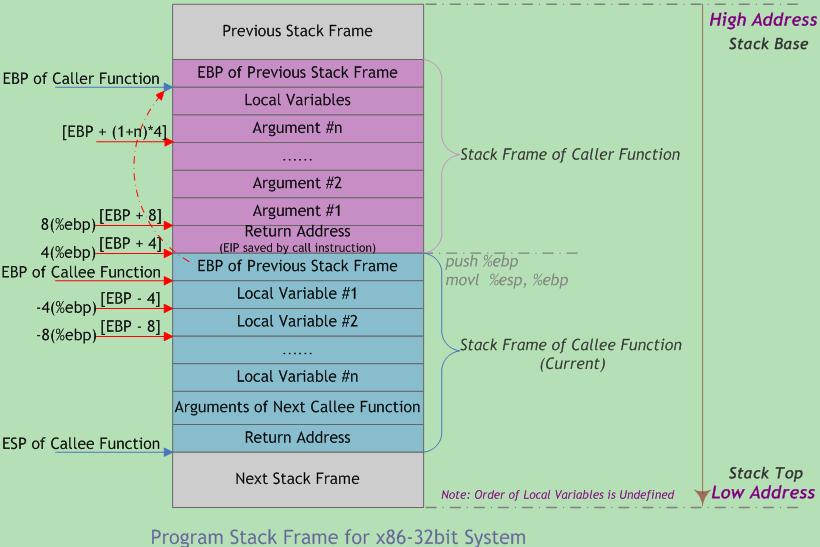
图中给出主调函数(Caller)(紫色部分)和被调函数(Callee)(蓝色部分)的栈帧布局。函数可以没有参数和局部变量,故图中”Argument(参数)“和”Local Variable(局部变量)“不是函数栈帧结构的必需部分。
函数调用时入栈顺序为:
实参N~1 → 主调函数返回地址 → 主调函数帧基指针EBP → 被调函数局部变量1~N
主调函数将函数参数(实参)按照调用约定依次入栈(图中传参调用约定为从右到左);然后将指令指针EIP入栈以保存主调函数的返回地址(下一条待执行指令的地址);进入被调函数时,被调函数将主调函数的帧基指针EBP入栈,并将主调函数的栈顶指针ESP值赋给被调函数的EBP(作为被调函数的栈底),接着改变ESP值来为函数局部变量预留空间。
此时被调函数帧基指针指向被调函数的栈底。以该地址为基准,向上(栈底方向)可获取主调函数的返回地址、参数值,向下(栈顶方向)能获取被调函数的局部变量值,而该地址处又存放着上一层主调函数的帧基指针值。本级调用结束后,将EBP指针值赋给ESP,使ESP再次指向被调函数栈底以释放局部变量;再将已压栈的主调函数帧基指针弹出到EBP,并弹出返回地址到EIP。ESP继续上移越过参数,最终回到函数调用前的状态,即恢复原来主调函数的栈帧。如此递归便形成函数调用栈。
2、函数调用约定
在 x86 架构下,函数调用约定常用的主要有以下四种。
| 调用约定 | 参数压栈顺序 | 栈清理方 | this 指针 / 寄存器传参 | 是否支持可变参数 | 主要应用场景 |
|---|---|---|---|---|---|
__cdecl |
右 -> 左 | 调用者 (Caller) | 无 | 是 | C/C++ 默认,printf 等 |
__stdcall |
右 -> 左 | 被调用者 (Callee) | 无 | 否 | Win32 API 核心约定 |
__thiscall |
右 -> 左 | 被调用者 (Callee) | ECX (MSVC) 或 栈底 (GCC) | 否 | C++ 非静态成员函数 |
__fastcall |
右 -> 左 | 被调用者 (Callee) | 前两个参数走 ECX, EDX | 否 | 性能要求极高的内部函数 |
注:
thiscall遇到可变参数时会自动转为调用者清栈。并不是thiscall本身能处理可变参数,而是当编译器发现你需要可变参数时,它会默默地把调用约定自动换成cdecl。
(1)__cdecl(C Declaration)
这是 C/C++ 的默认调用约定。
- 参数传递:从右向左压入栈(Stack)。
- 栈清理:调用者(Caller)清栈。
- 核心特点 - 支持可变参数:因为是调用者清栈,调用者清楚自己到底压了多少个参数进去,所以它是唯一能原生支持可变参数(如
printf(const char* format, ...))的调用约定。 - 缺点:每次调用后都需要生成清理栈的汇编代码(如
add esp, 8),这会导致编译出的可执行文件体积稍大。
(2)__stdcall (Standard Call)
这是 Windows API 默认使用的调用约定(宏 WINAPI 和 CALLBACK 通常会被解析为 __stdcall)。
- 参数传递:从右向左压入栈。
- 栈清理:被调用者(Callee)清栈(函数返回时通过
retn指令完成)。 - 核心特点 - 体积更小:因为清栈的代码写在函数内部的末尾,无论外部调用多少次,清栈代码只有一份,所以生成的代码体积比
cdecl小。 - 限制:不支持可变参数。被调用者在编译时必须知道参数的总大小才能生成正确的
ret n指令。
(3)__thiscall
这是 C++ 中非静态成员函数的默认调用约定,专门为了处理 this 指针而生。
- 参数传递:从右向左压入栈。
this指针传递(关键差异):- MSVC 编译器(Windows):
this指针通过 ECX 寄存器传递。 - GCC/Clang 编译器(Linux/Mac):没有真正的
thiscall,它本质上把this当作函数的第一个隐藏参数,直接最后(也就是最先出栈的位置)压入栈中。
- MSVC 编译器(Windows):
- 栈清理:默认情况下,被调用者(Callee)清栈(类似
stdcall);但如果该成员函数包含可变参数(...),则自动降级为由调用者(Caller)清栈(类似cdecl)。
(4)__fastcall
顾名思义,为了“快”而设计的调用约定,通过寄存器传参来减少内存(栈)访问。
- 参数传递:
- 前两个(或几个,取决于编译器)小于等于 32 位(DWORD)的参数,直接通过寄存器传递。超出部分或过大的参数,依然从右向左压入栈。
- MSVC:前两个参数使用 ECX 和 EDX 寄存器。
- 栈清理:被调用者(Callee)清栈。
在 x86 架构下,Windows 与 Linux 函数调用约定的使用情况。
(1)Linux 32 位程序
- C 函数默认基本是
__cdecl - 普通 C 函数很少用
__stdcall,除非显式指定或兼容特定接口
(2)Windows 32 位程序
- C/C++ 普通函数常见
__cdecl - WinAPI 函数常见
__stdcall - C++ 成员函数常见
__thiscall - 部分 C/C++ 函数也可能显式使用
__fastcall
在 x86 架构下,__cdecl 与 __stdcall 共同的传参示例如下。 它们的传参压栈顺序是一样的,区别在于清栈方式上。
|
|
3、函数栈布局
一个典型的 x86 程序 main 函数栈的布局如下图所示:
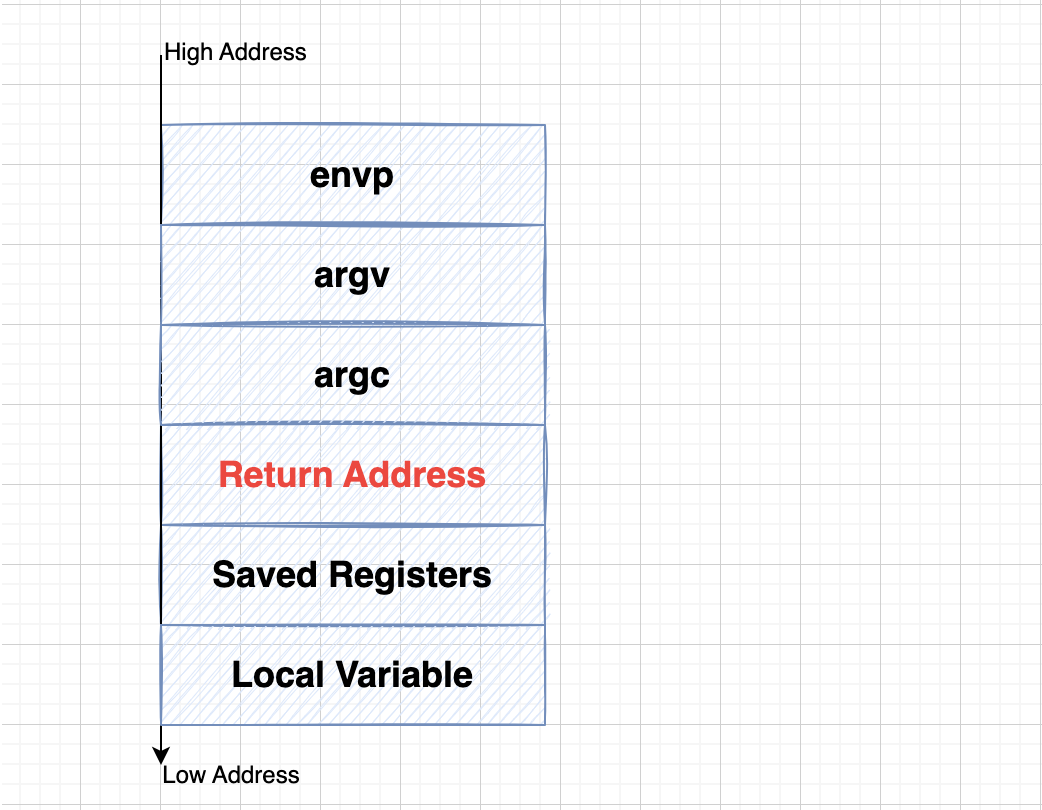
(1)栈增长方向
栈在内存中是“从高地址向低地址增长”的,符合图中自上而下,从高地址→低地址的视图结构。
(2)栈布局说明
-
envp(环境变量指针)
-
类型:
const char **envp -
含义:传递给 main 函数的环境变量数组(如 PATH=/usr/bin 等)
-
-
argv(参数数组)
-
类型:
const char **argv -
含义:命令行参数数组,例如程序名和参数(./prog abc def)
-
-
argc(参数个数)
-
类型:
int argc -
含义:命令行参数的数量
-
-
Return Address(返回地址)
-
含义:函数返回后跳转到调用者的位置
-
压栈方式:由 call 指令自动压栈(call main → 返回地址 push 到栈上)
-
-
Saved Registers(保存的寄存器)
-
通常为:old EBP,也存在其他寄存器状态需要保存的情况。
-
含义:保存调用者的栈基址(使得 ebp 能恢复),一般在函数开头:push ebp
-
-
Local Variable(局部变量区)
-
向下分配空间:
sub esp, xx为局部变量留空间 -
变量如:char buf[100], int tmp 等
-
这是最可能被溢出攻击利用的区域
-
(3)程序栈示例
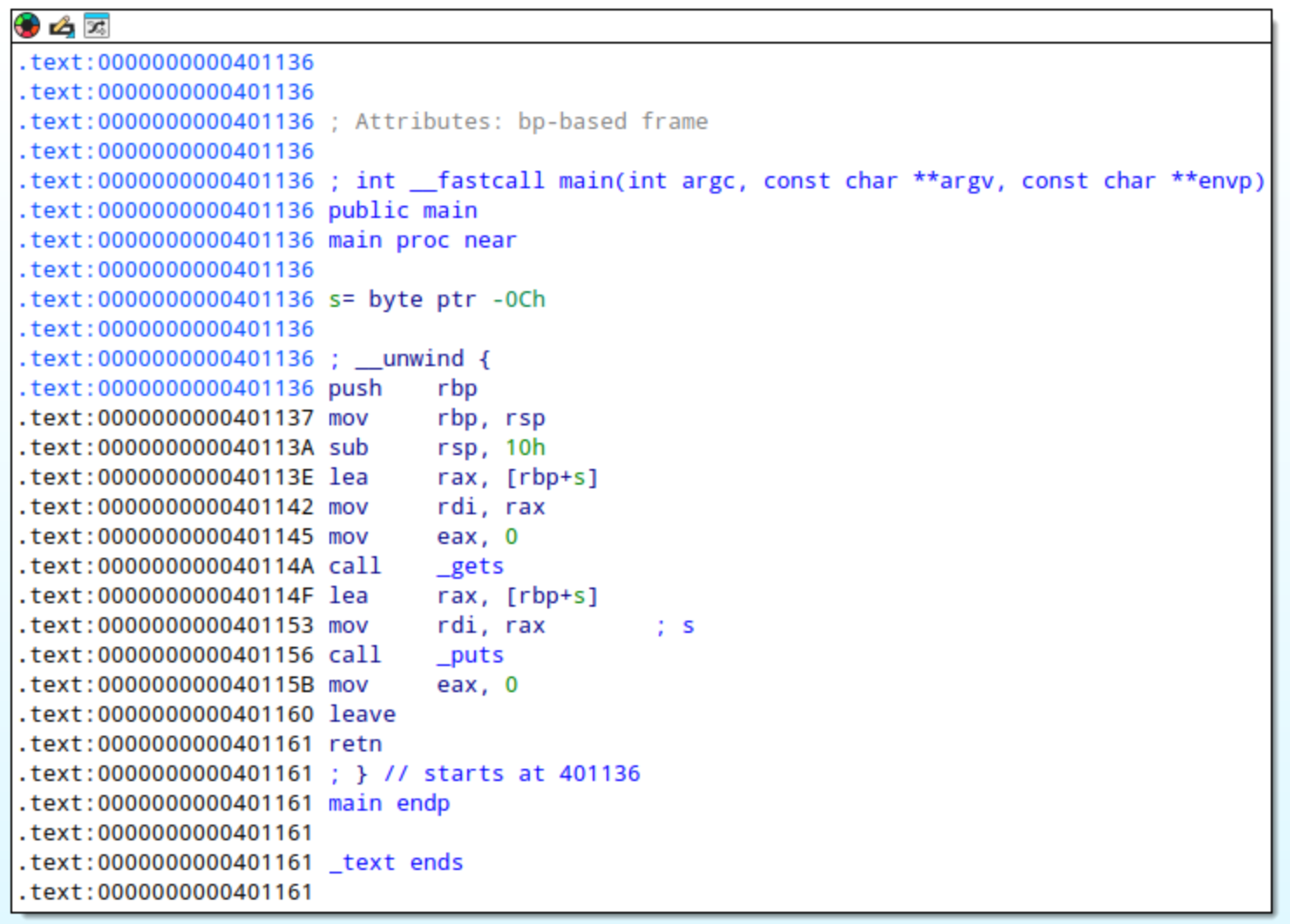
我们用到的示例程序(Function)的代码:
|
|
buffer[12]是一个局部变量,在栈中分配空间;- 调用
gets()时,用户输入的数据被写入栈上的 buffer 区域; puts()只是把 buffer 打印出来;- 该函数在调用时会构造栈帧:包括参数(
envp、argc、argv)、返回地址、旧的 EBP 以及 buffer 所在的局部变量区。
Linux下编译该程序:
|
|
使用IDA Pro分析该程序。
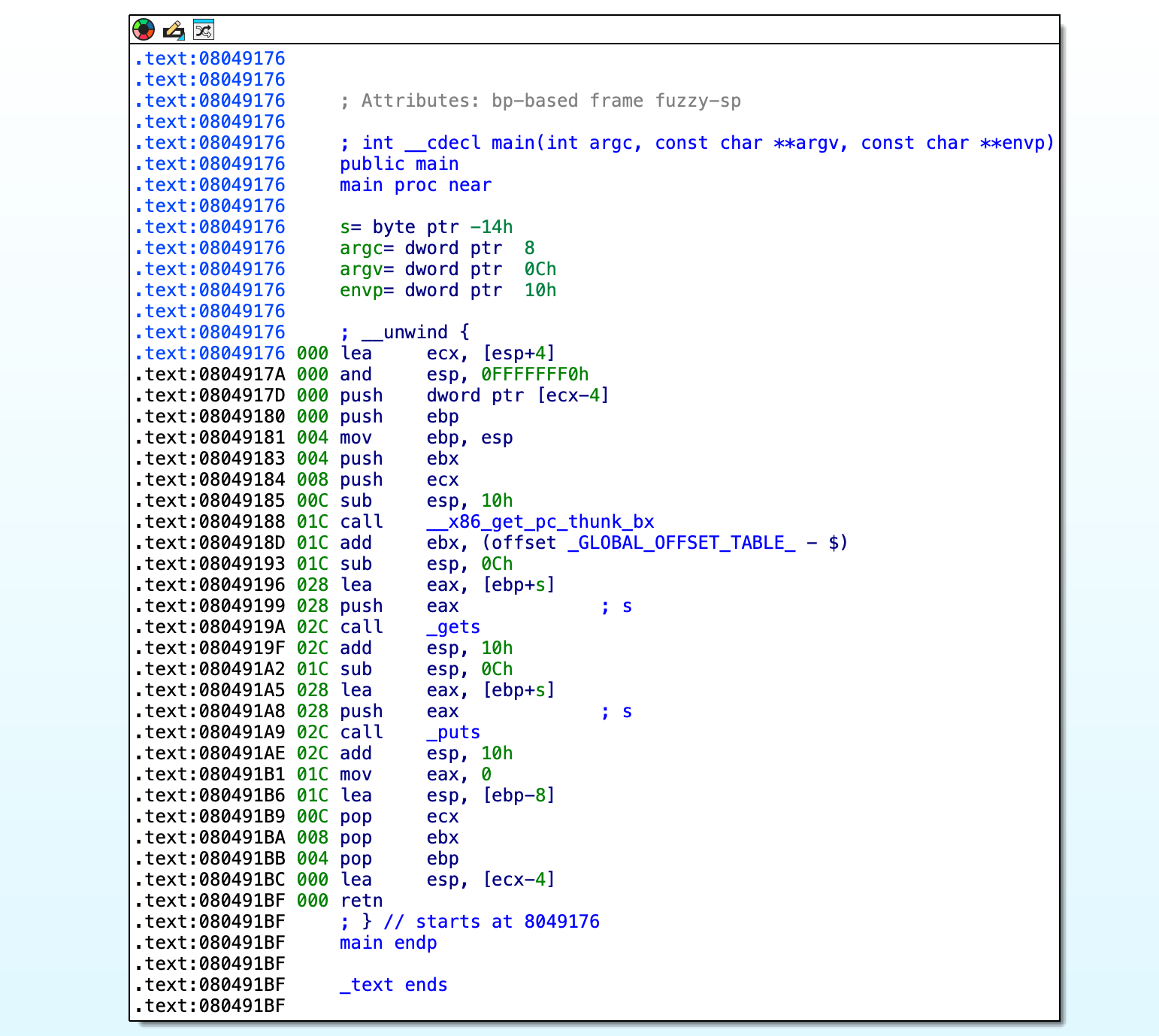
建议将IDA Pro识别出的传给 gets 函数的缓存区变量s,直接重命名为buffer,这会使代码更容易理解。
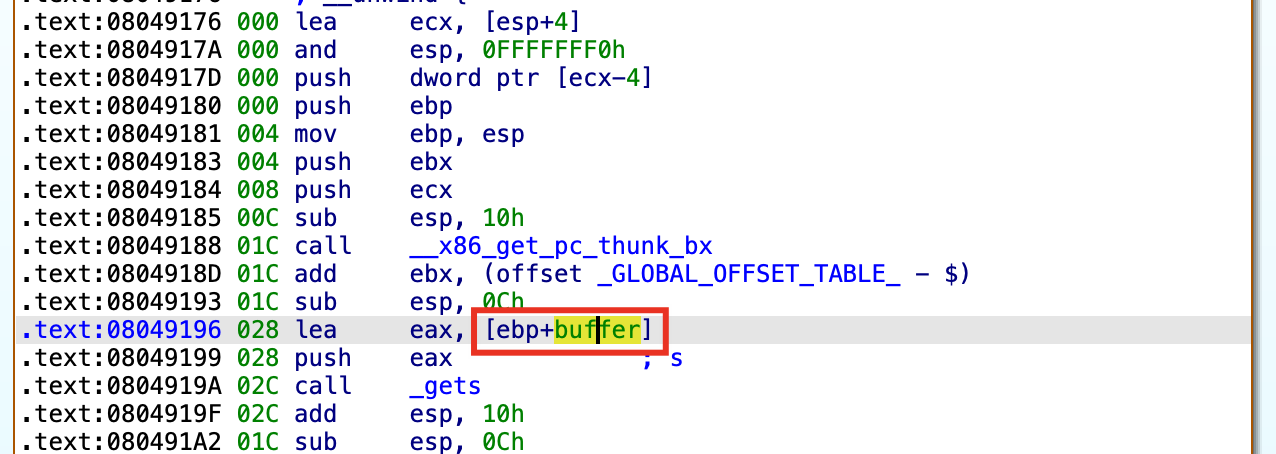
双击 buffer 变量的位置,即可跳转到IDA Pro的静态栈视图。
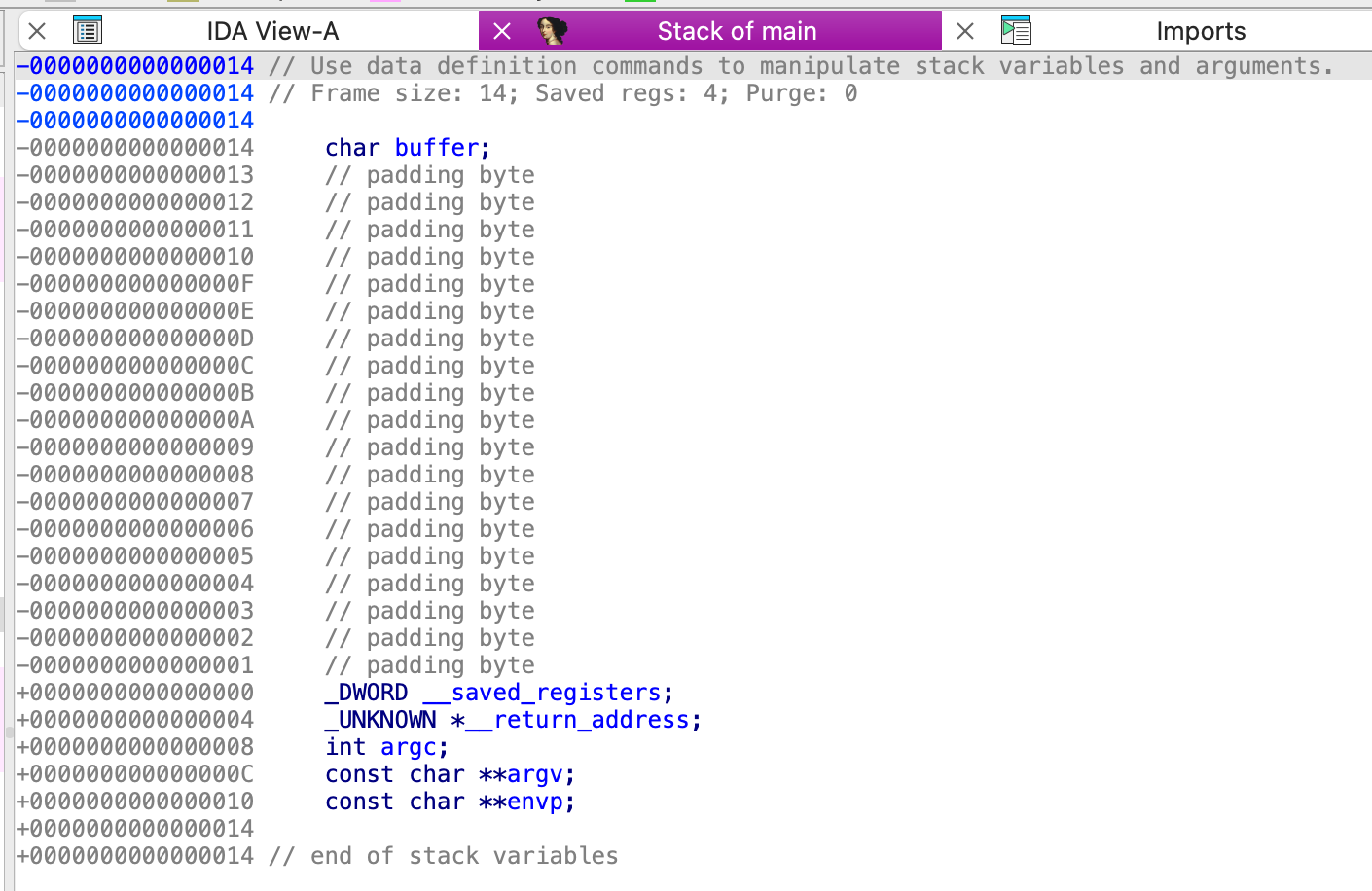
在静态栈视图中,我们可以看到该函数调用时的基本栈布局信息,比如buffer、saved registers、return address、argc、argv、envp是怎么布局的。但需要注意的是IDA Pro静态栈视图是从低地址到高地址表示的,习惯上我们一般会按照自上而下,从高地址→低地址的顺序去制图,所以,需要我们去画一下栈布局。
需要注意的是,本程序中保存到栈上的寄存器不仅只有ebp,还有ebx,ecx。我们需要根据实际的栈布局情况去绘图。
|
|
| 项目 | 大小 | 位于栈上的偏移范围(相对 EBP) |
|---|---|---|
envp |
4 字节 | [ebp+10h] |
argv |
4 字节 | [ebp+0Ch] |
argc |
4 字节 | [ebp+08h] |
| 返回地址 | 4 字节 | [ebp+04h] |
| 调用者的 EBP(old) | 4 字节 | [ebp+00h] |
| 保存的 EBX | 4 字节 | [ebp-04h] |
| 保存的 ECX | 4 字节 | [ebp-08h] |
char buffer[12] |
12 字节 | [ebp-14h] 到 [ebp-09h](从低地址向上) |
在调用 main 函数之前,程序会将函数参数envp、argc、argv依次压栈。
接着,程序调用call指令或其他方式把返回地址压栈。
call指令有两个功能:第一个是执行call指令后,程序会跳转到指定的要调用的函数地址去执行;第二个是会将该函数调用结束后要执行的指令(也就是返回地址)保存到栈上。
最后,程序会在 main 函数中使用push、sub等指令完成对栈的布局。
在 main 函数中,我们重点关注导致函数栈发生变化的几条指令:
.text:08049180 000 push ebp
.text:08049181 004 mov ebp, esp
.text:08049183 004 push ebx
.text:08049184 008 push ecx
.text:08049185 00C sub esp, 10h
.text:08049188 01C call __x86_get_pc_thunk_bx
push ebp 指令
作用:保存旧栈基址,以便后续能恢复;
将调用者的 EBP 值压入栈中(4字节);栈指针 ESP = ESP - 4,IDA 视图中显示为000到004。
mov ebp, esp 指令
作用:建立当前函数的局部变量/参数访问基准;
用当前 ESP 值作为新栈帧基址;不会影响栈内容,但会让程序以 EBP 为基准来布局栈帧。
push ebx 指令
作用:保存调用者的 EBX 寄存器内容(callee-saved 寄存器);
栈又下移 4 字节;栈指针 ESP = ESP - 4,IDA 视图中显示为004到008。
push ecx 指令
作用:保存 ECX 的值;
栈再下移 4 字节;栈指针 ESP = ESP - 4,IDA 视图中显示为008到00C。
sub esp, 10h 指令
作用:为局部变量预留 0x10 字节(16 字节)空间;
栈再下移 16 字节;栈指针 ESP = ESP - 16,IDA 视图中显示为008到00C。
至此,在x86程序中,一个典型的 main 函数调用过程中的栈布局介绍完成。
三、x64 程序栈布局
1、函数调用栈
x64 程序的函数调用栈与 x86 在整体思想上是一致的:函数调用时会形成栈帧,栈帧中保存返回地址、旧的栈基址、局部变量、临时数据以及必要的寄存器状态。
但 x64 与 x86 有几个非常重要的区别:
- 指针和地址宽度从 4 字节变成 8 字节;
- 函数参数优先通过寄存器传递,而不是全部压栈;
- 返回地址仍然由
call指令自动压栈,但大小变成 8 字节; - 栈指针从
ESP变成RSP,帧基指针从EBP变成RBP; - x64 编译器经常省略
RBP作为帧基指针,直接基于RSP访问局部变量。
在 x64 中,call 指令的作用仍然是:将下一条指令地址压入栈中,作为返回地址;跳转到目标函数执行。ret 指令则是:从栈顶弹出 8 字节返回地址,并跳转到该地址继续执行。
一个使用 RBP 的典型 x64 函数栈帧如下:
|
|
需要注意的是,在 x64 下,前几个参数通常已经不在 [rbp+08h]、[rbp+0Ch] 这种位置了,而是放在寄存器中。
例如 Linux x64 下,前 6 个整数或指针参数通常在:
rdi, rsi, rdx, rcx, r8, r9
Windows x64 下,前 4 个整数或指针参数通常在:
rcx, rdx, r8, r9
所以分析 x64 函数时,不能再简单套用 x86 中“参数都在栈上”的思路。
另外,x64 下还有一个非常重要的规则:栈通常需要保持 16 字节对齐。编译器在函数调用前后经常会额外调整 rsp,这些空间不一定都是局部变量,也可能只是为了满足栈对齐要求。
2、函数调用约定
在 x64 架构下,函数调用约定常用的主要有以下两种。
(1)System V AMD64 ABI
- Linux、macOS、BSD 常用
- 整数/指针参数主要用:RDI, RSI, RDX, RCX, R8, R9
- 浮点参数用:XMM0-XMM7 寄存器
- 有 128 字节 red zone(栈空间优化技术,它允许函数直接使用当前栈指针(
%rsp)下方 128 字节的空间,而无需提前移动栈指针)
(2)Microsoft x64 calling convention
- Windows x64 常用
- 前四个整数/指针参数用:RCX, RDX, R8, R9
- 浮点参数用:XMM0-XMM3 寄存器
- 调用者必须预留 32 字节 shadow space(调用者在调用函数前,必须在栈上预留 32 字节空间,供被调用函数保存 RCX、RDX、R8、R9 这 4 个寄存器参数使用。即使被调用函数不使用这块空间,调用者也必须预留)
Linux 调用示例:
|
|
那么可以理解为:
|
|
Windows 调用示例:
|
|
那么可以理解为:
|
|
3、函数栈布局
继续使用前面的示例程序,只是这次编译为 x64 程序。
|
|
Linux x64 下编译:
gcc -fno-stack-protector -fno-omit-frame-pointer -no-pie -z execstack -Wno-implicit-function-declaration Function64.c -o Function64
- -fno-stack-protector:关闭栈保护;
- -fno-omit-frame-pointer:保留 rbp,方便观察栈帧;
- -no-pie:关闭 PIE,方便静态分析;
- -z execstack:允许栈可执行;
- -Wno-implicit-function-declaration:忽略 gets() 隐式声明警告。
在 Linux x64 的 System V AMD64 ABI 中,main 函数的前三个参数(argc、argv、envp)并不是通过栈传递的,而是通过寄存器传递的:
edi = argc
rsi = argv
rdx = envp
所以在本程序的栈布局中,我们主要关注:返回地址、old rbp、局部变量 buffer、padding。
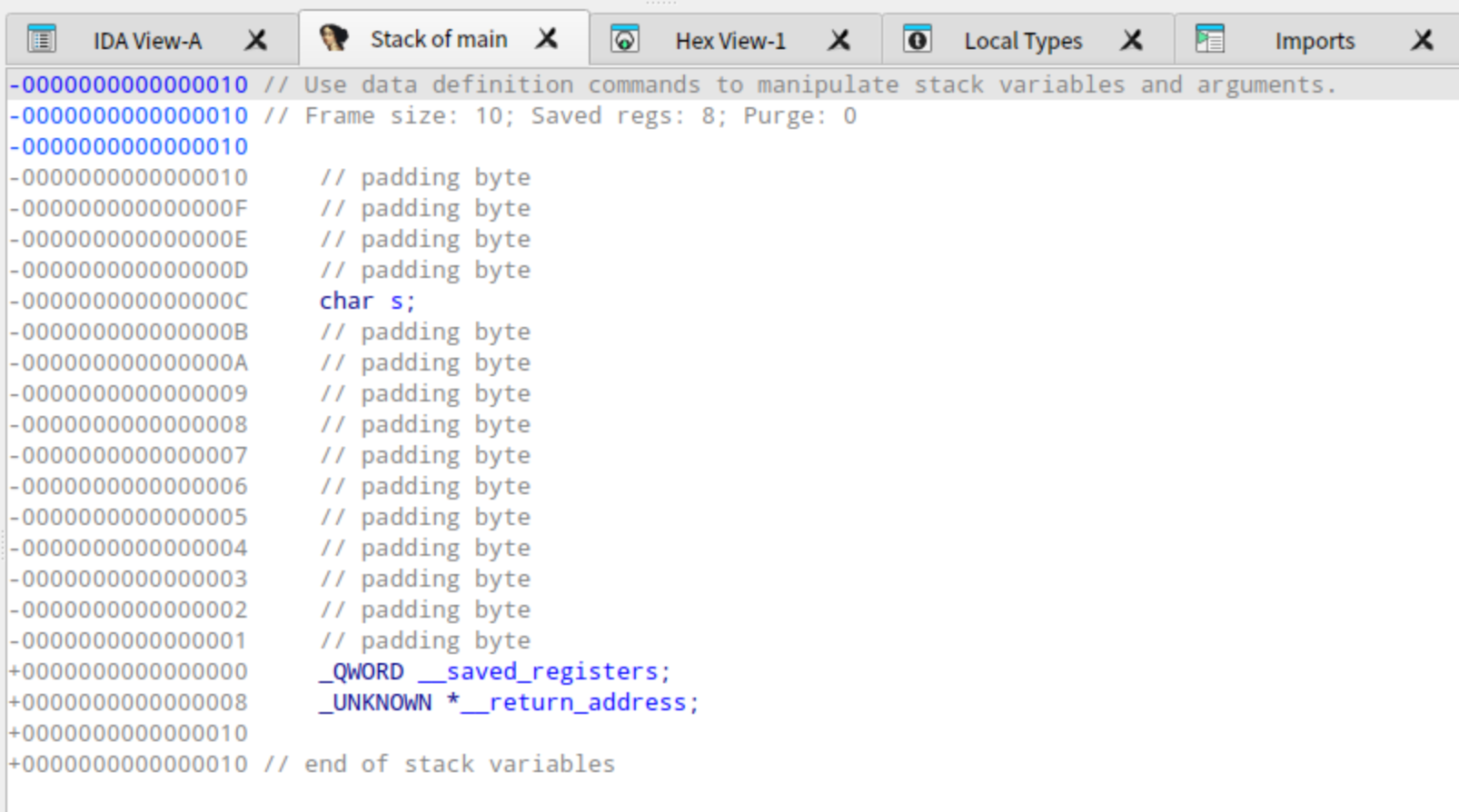
对应的栈布局如下:
|
|
| 项目 | 大小 | 位于栈上的偏移范围 |
|---|---|---|
| 返回地址 | 8 字节 | [rbp+08h] |
| 调用者的 RBP | 8 字节 | [rbp+00h] |
| char buffer[12] | 12 字节 | [rbp-0Ch] 到 [rbp-01h] |
| padding / 对齐空间 | 4 字节 | [rbp-10h] 到 [rbp-0Dh] |
虽然 buffer 只有 12 字节,也就是 0Ch,但编译器这里分配了 10h 字节,也就是 16 字节。多出来的 4 字节通常用于 padding 或栈对齐。
接着看 gets(buffer) 的传参方式。
x86 中通常会把 buffer 的地址压栈:
lea eax, [ebp-14h]
push eax
call gets
而 Linux x64 中,第一个参数通过 rdi 传递:
lea rax, [rbp-0Ch]
mov rdi, rax
call gets
两者传递的都不是 buffer 的完整内容,而是 buffer 的地址。区别在于:
x86:把 buffer 的地址压入栈中作为参数;
x64:把 buffer 的地址放入 rdi 寄存器作为参数。
当 gets(buffer) 接收用户输入时,数据会从 buffer[0] 开始向高地址连续写入:
低地址 → 高地址
buffer[0]
buffer[1]
...
buffer[11]
old rbp
return address
至此,在 x64 程序中,一个典型的 main 函数调用过程中的栈布局介绍完成。
四、Linux 程序保护机制
使用命令checksec可以查看程序开启的保护机制:
pip3 install pwntools 后即可使用附加工具 checksec
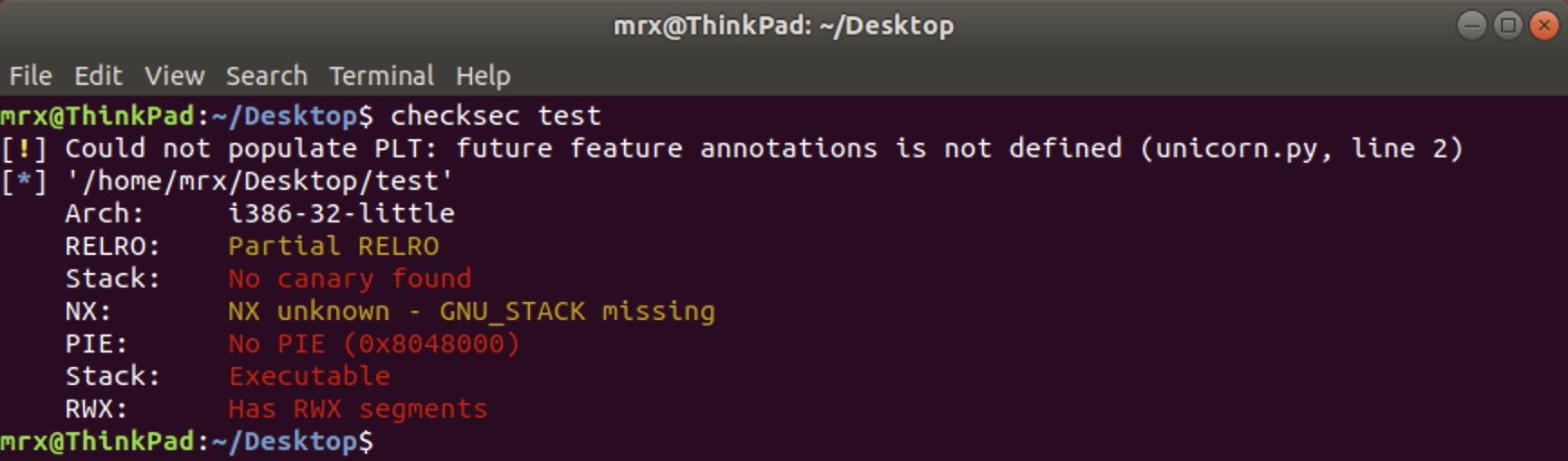
1、Canary 保护机制
Stack Canary(栈金丝雀)是一种重要的计算机安全机制,旨在防止缓冲区溢出攻击,特别是栈溢出攻击。其名称源于矿工在矿井中携带金丝雀,以便在有毒气体泄漏时,金丝雀比人类更早感知并发出警告。同理,栈金丝雀在程序栈中充当“早期预警系统”,用于检测栈溢出行为。
在启用栈保护的程序中,每当函数被调用时,编译器会在栈帧中插入一个特殊的值(即“金丝雀”)。当函数返回时,程序会检查该值是否被篡改。如果发现金丝雀值被修改,程序会认为发生了栈溢出攻击,立即终止执行,以防止攻击者利用溢出覆盖返回地址等关键数据。
在启用栈保护的情况下,x86 程序的 main 函数栈结构如下图所示:

|
|
__stack_chk_guard 或 __security_cookie 是由编译器随机生成的一个值。
Canary 值位于返回地址前面,局部变量后面。攻击者若要覆盖返回地址,必须首先覆盖 Canary 值,从而触发栈保护机制。
Canary 保护在Linux下被称为Stack Canaries 保护,在Windows被称为GS 保护。
根据生成方式的不同,可以将 Stack Canaries 分为三类:Terminator Canary(终止符金丝雀)、Random Canary(随机金丝雀)、Random XOR Canary(随机异或金丝雀)
-
Terminator Canary(终止符金丝雀):这种 Canary 是一个固定的值,通常是0或者一些字符串终止符(如0x00, 0xFF, 0x0A, 0xFF)。这种 Canary 的优点是可以防止一些基于字符串操作的缓冲区溢出攻击,因为这些操作会在遇到终止符时停止。但该方式容易被攻击者预测和绕过。
-
Random Canary(随机金丝雀): 为防止 Canary 的值被攻击者猜到,这种方式的 Canary 是一个随机生成的值,会在程序初始化时随机生成,增加了攻击者猜测的难度。通常使用
/dev/urandom或当前时间的哈希值生成。 -
Random XOR Canary(随机异或金丝雀):在随机生成的 Canary 值的基础上,与栈帧中的控制数据(如返回地址、帧指针等)进行异或操作。这种方式增加了攻击的复杂度,即使攻击者获取了 Canary 值,也难以利用。
一般情况下,Stack Canaries/GS 保护机制会在函数开始执行的时候先往栈底插入一个 cookie 值,这个 cookie 值就被称为 Canary。用于检测缓冲区溢出,以及防止攻击者利用缓冲区溢出攻击,从而执行恶意代码。
(1)Windows GS 保护
|
|
如下所示,示例为32位Windows应用程序(Windows-GS.exe)在_main函数中的GS保护。
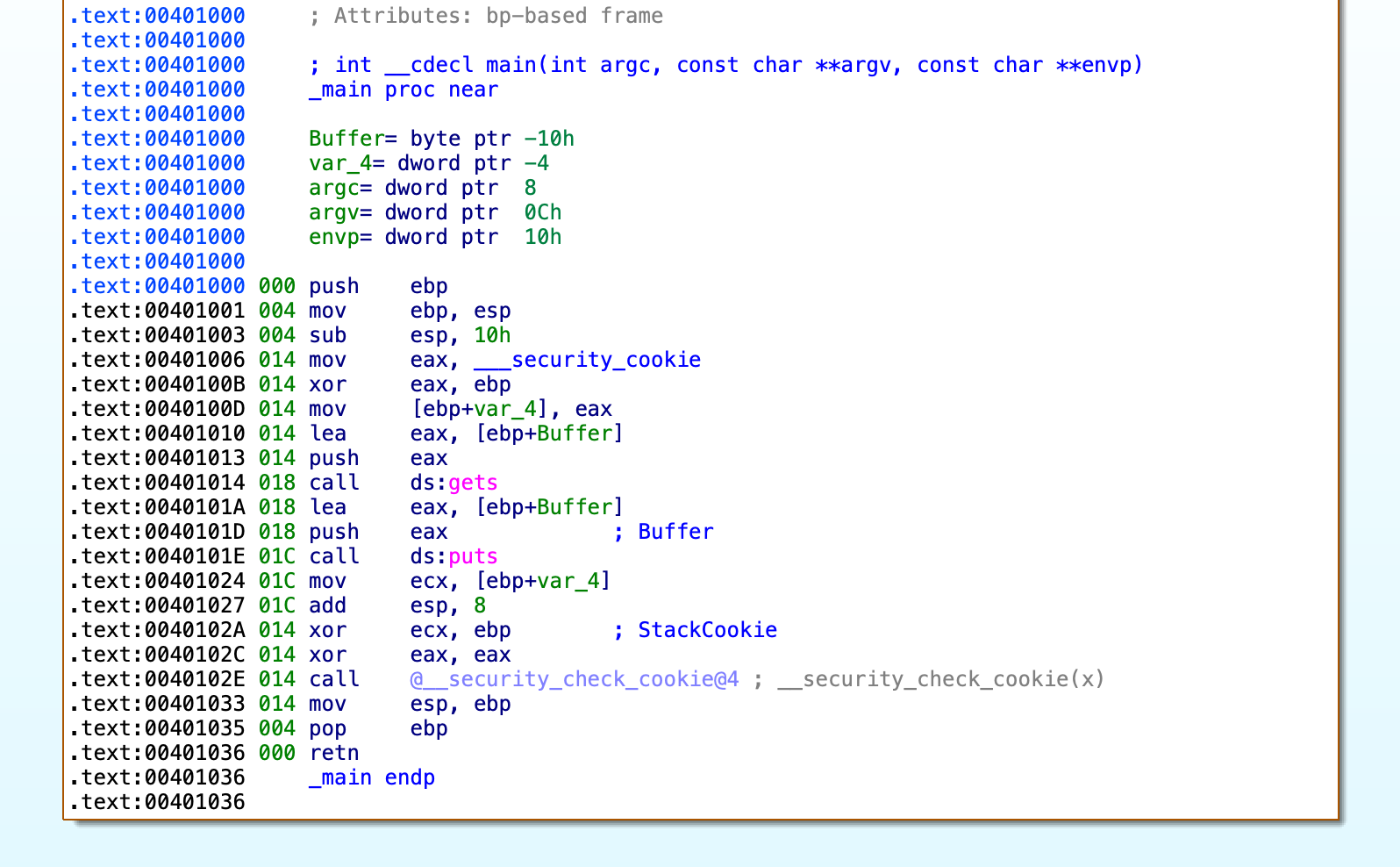
在_main函数中,程序会从__security_cookie全局变量中获取随机数,然后将其赋值给 EAX 寄存器。接着将其与此时 EBP 的值进行异或运算,并将得到的结果存放到 EAX 寄存器中。最后,将 EAX 中的值存放到栈上的 cookie(原var_4) 变量中。
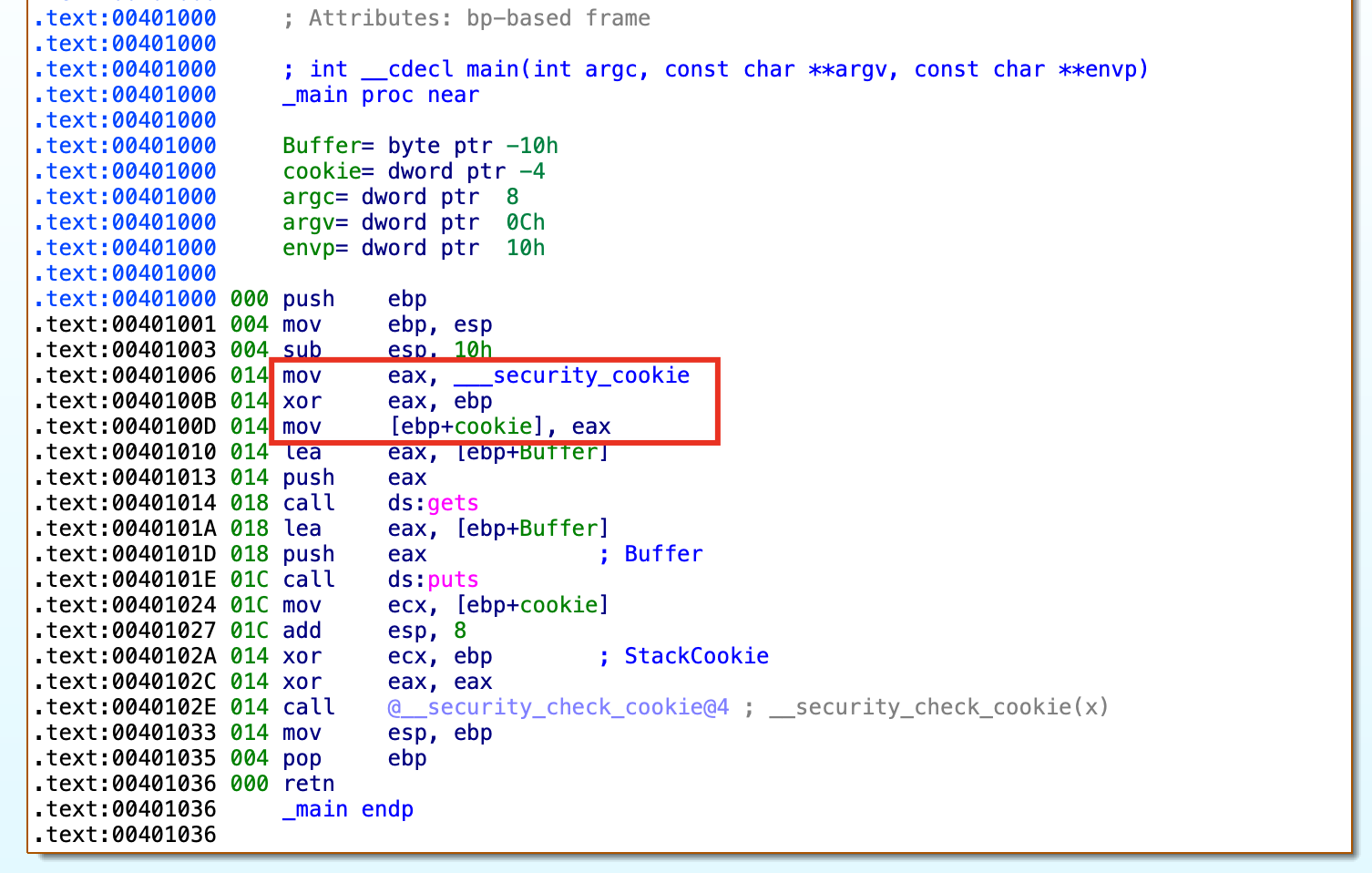
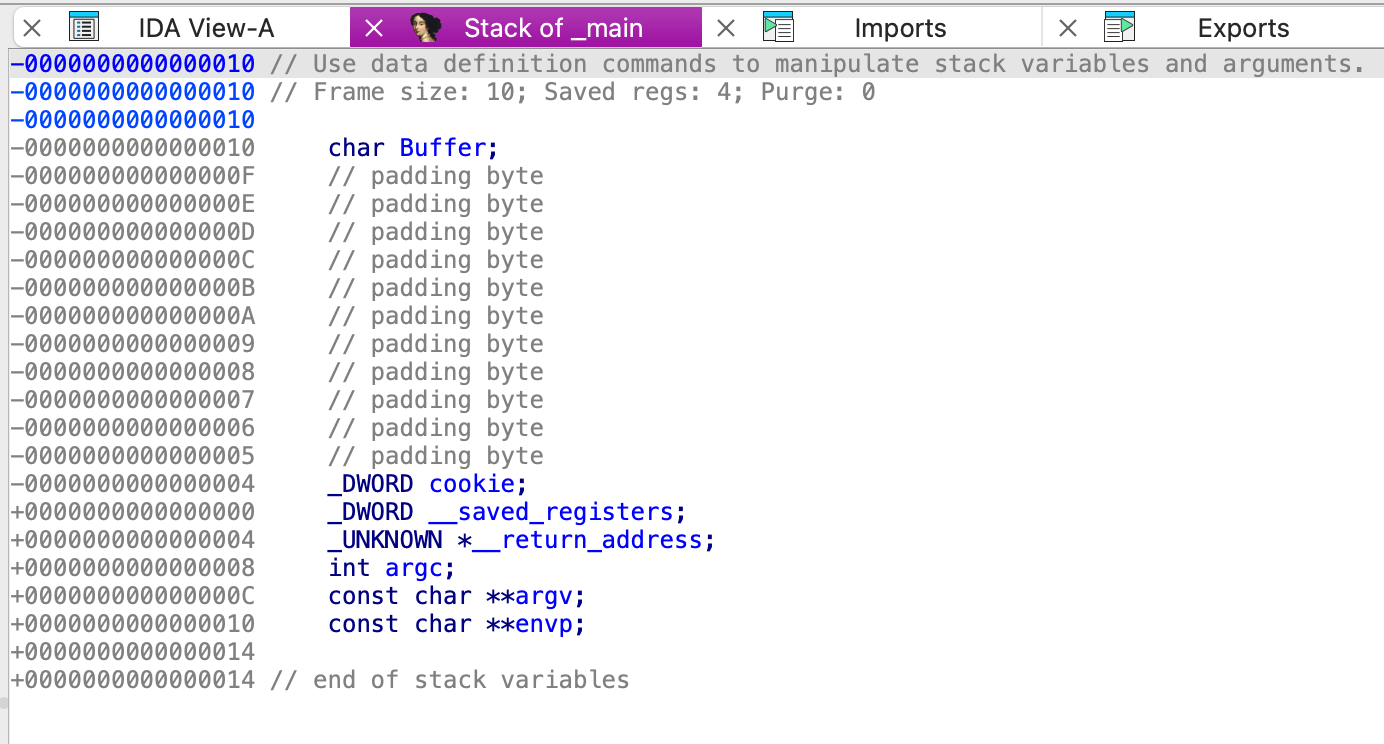
双击变量cookie,就可以跳转到IDA Pro的静态栈视图进行查看(可结合前面提到的Canary保护机制视图对比查看)
|
|
其中伪C代码中的索引[ebp+cookie]就是cookie变量在栈中[ebp-04h]的位置。
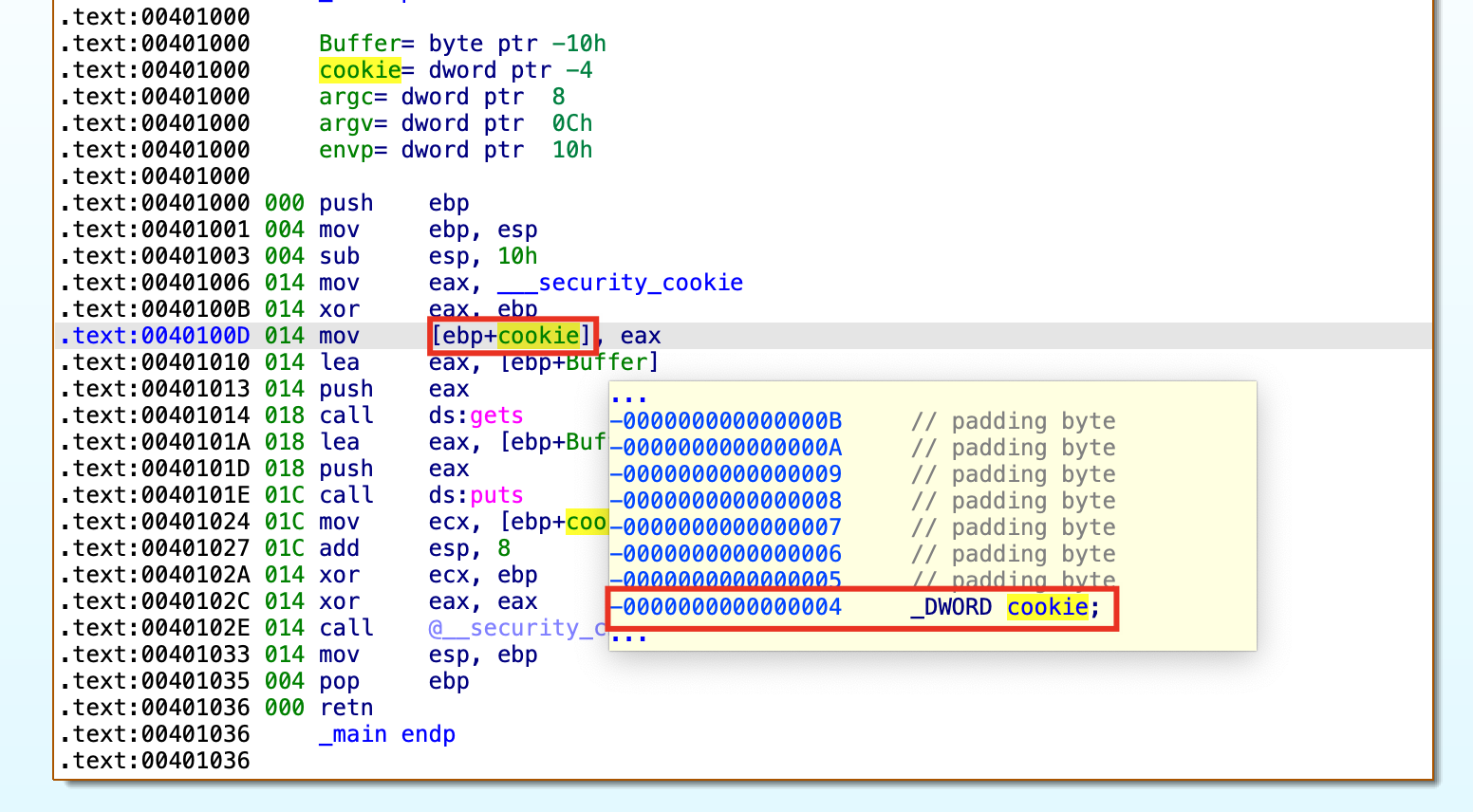
程序会在_mian函数代码执行完返回前,对 cookie 的值进行校验。首先会将当前 cookie 的值从栈上取出并存放到 ECX 寄存器中,然后将 ECX 中的值与此时 EBP 的值(EBP的值在当前_main函数内始终不变)进行异或运算(还原cookie值),得到的结果存放到 ECX 中。接着会调用 __security_check_cookie 函数对 cookie 的值进行校验。
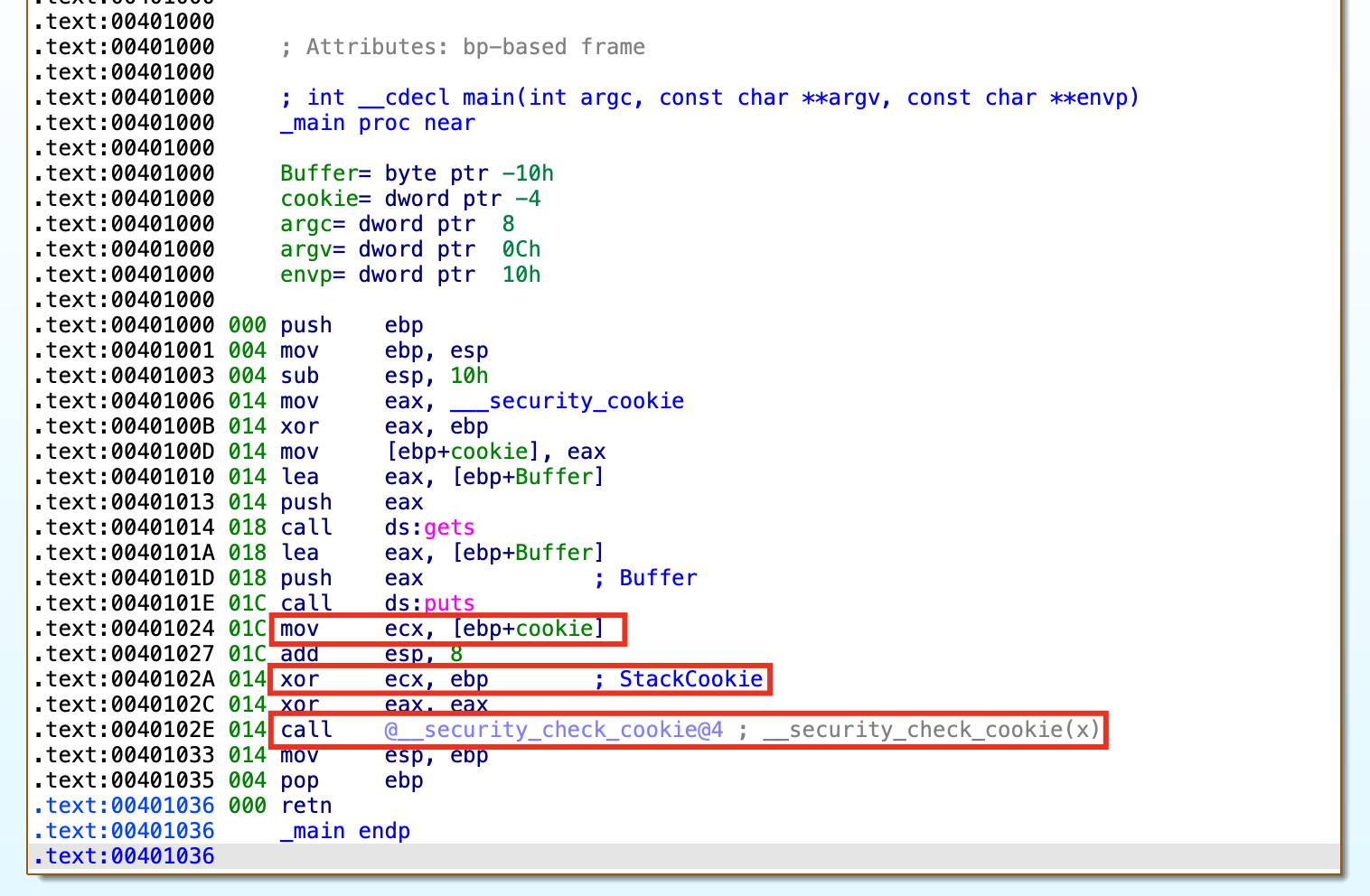
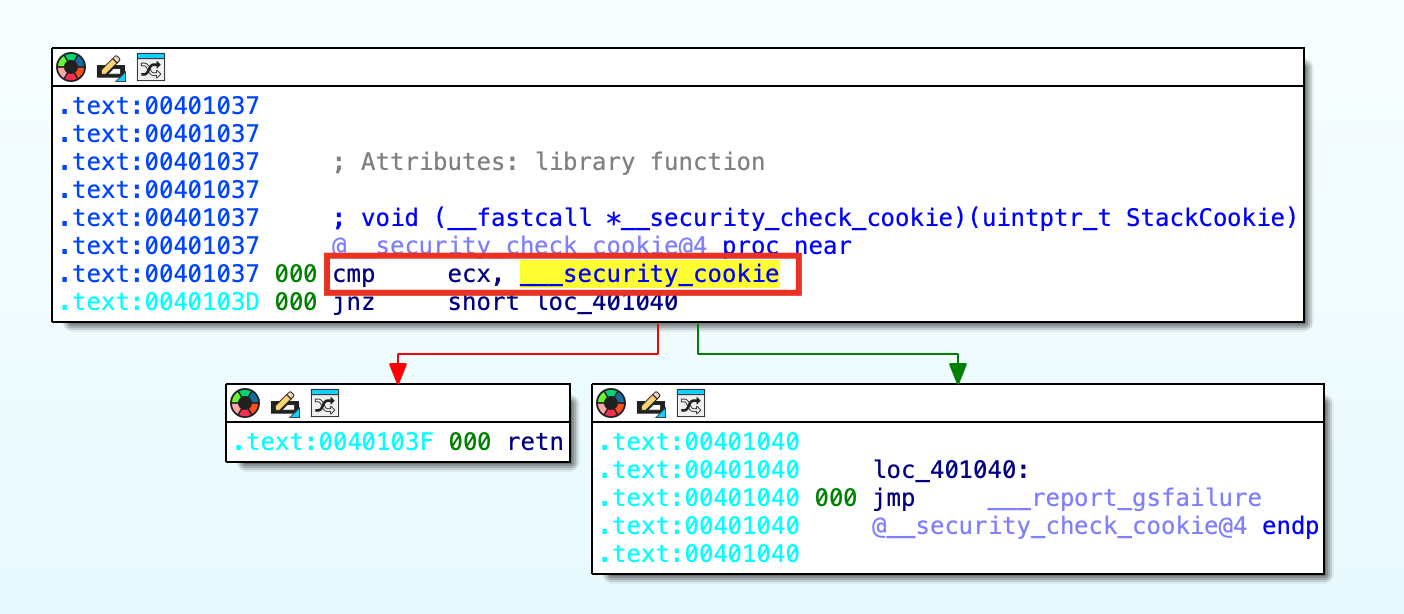
在__security_check_cookie函数中,如果此时 ECX 中保存的 Cookie 值和最初的 __security_cookie全局变量中获取的随机数相同,就返回正常;如果不同就会跳转到___report_gsfailure导致程序异常退出。
上面连续出现了5条汇编指令:
mov ecx, [ebp+cookie]
add esp, 8
xor ecx, ebp ; StackCookie
xor eax, eax
call @__security_check_cookie@4 ; __security_check_cookie(x)
其中有关 cookie 校验的关键指令为前面图片中标红的指令:
mov ecx, [ebp+cookie]
xor ecx, ebp ; StackCookie
call @__security_check_cookie@4 ; __security_check_cookie(x)
针对这5条汇编指令解释:
mov ecx, [ebp+cookie]
作用:从栈中取出原先保存的 canary 值(进入函数时写入的);将其保存到 ecx 中,准备做检查。
add esp, 8
作用:恢复栈空间,因为程序前面通过 call 调用了gets和 puts函数,调用这两个函数前都push eax(参数)了一次,一次就会占用栈空间 4 字节,所以总共占用栈空间 8 字节;这一步就是清理参数,调整 esp 回到调用gets和 puts函数前的状态。
xor ecx, ebp
作用:取出栈上的 cookie 后,还原原始的 cookie 值ecx = (cookie_on_stack) ^ ebp。因为函数开始时存的是 cookie ^ ebp,所以现在用 ecx ^ ebp 恢复原始值;同时,为下个函数 __security_check_cookie(ecx) 做准备。
xor eax, eax
作用:将 eax 置 0;有些调用约定要求:eax 为 0 表示正常返回;在这里不关键,但多数是为了约定或语义明确。
call @__security_check_cookie@4
作用:调用实际的栈保护检查函数。cookie值如果一致 → 安全,继续执行;cookie值如果不一致 → 说明栈被篡改,程序终止,通常调用__report_gsfailure或直接崩溃。
(2)Linux Stack Canaries 保护
|
|
如下所示,示例为32位Linux应用程序(Linux-Canaries)在_main函数中的GS保护。
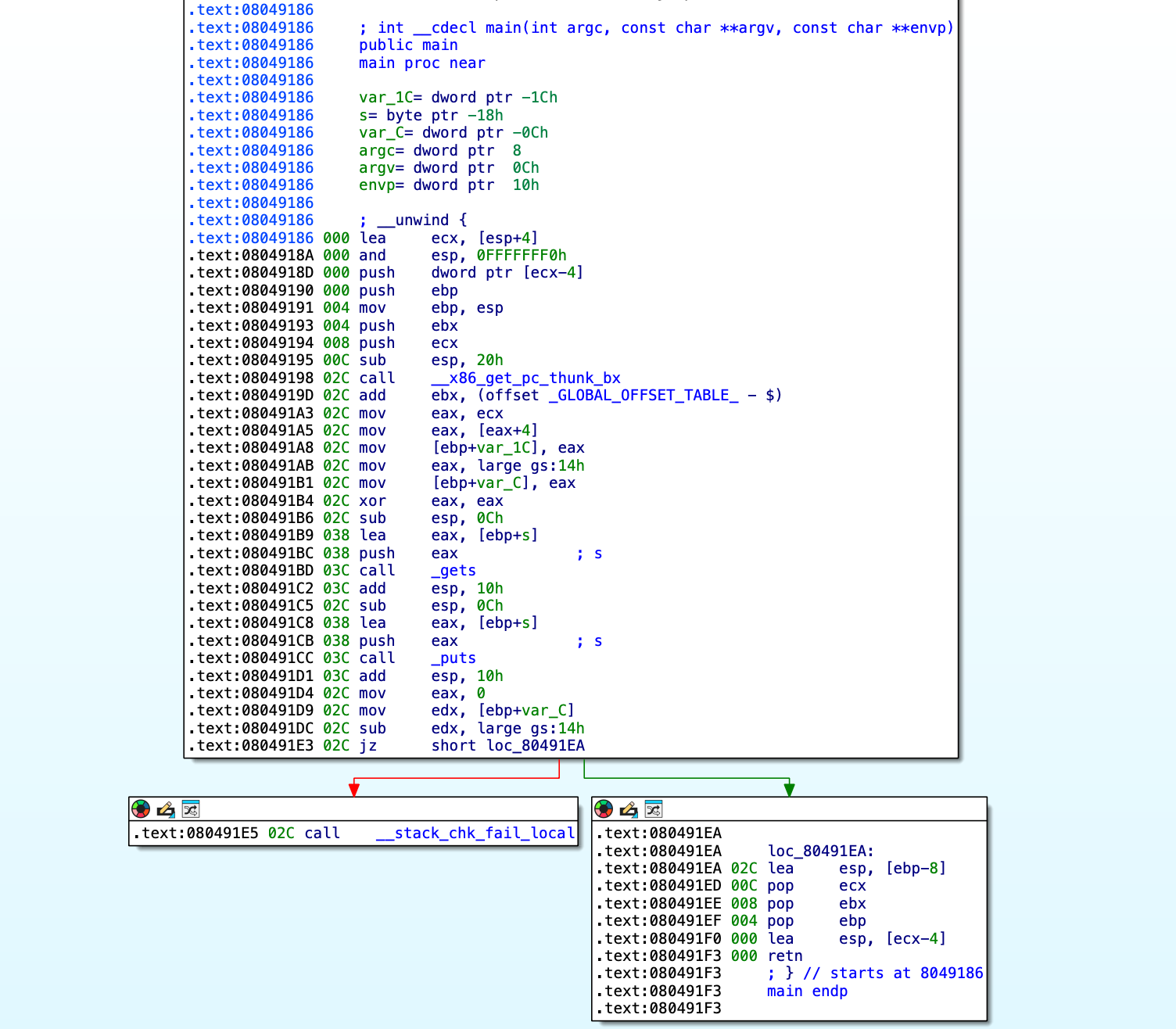
在main函数中,程序首先通过mov eax, large gs:14h指令,从段寄存器GS的偏移0x14处获取全局的stack canary值(这是线程局部存储中的栈保护值),将其存入 EAX 寄存器。随后,将该值保存在当前函数栈帧的局部变量 [ebp+canary](原[ebp+var_C]变量)中,用作进入函数前对 canary 值的保存。
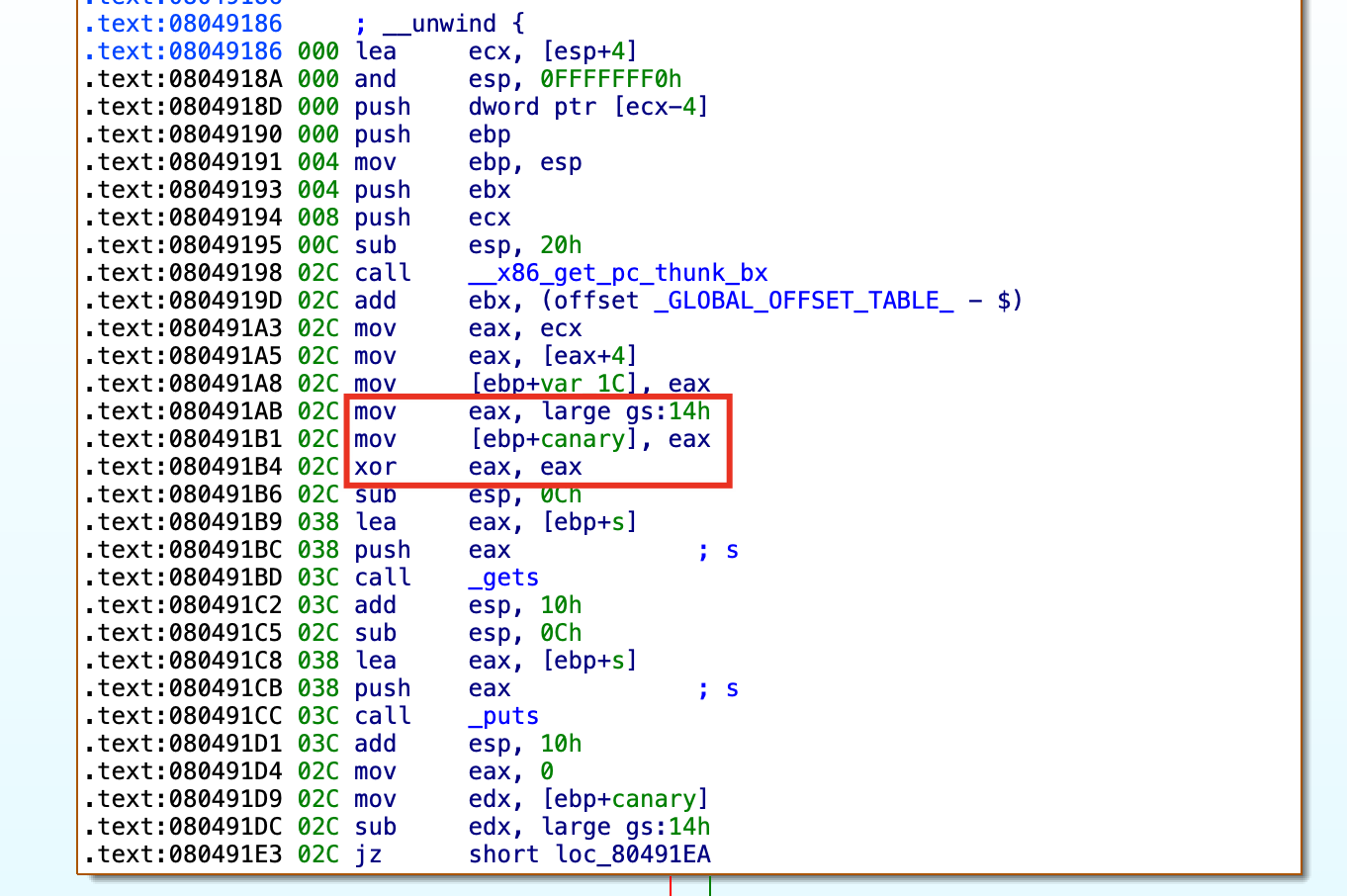
其中,gets函数和puts传递的变量s已被重命名为buffer。
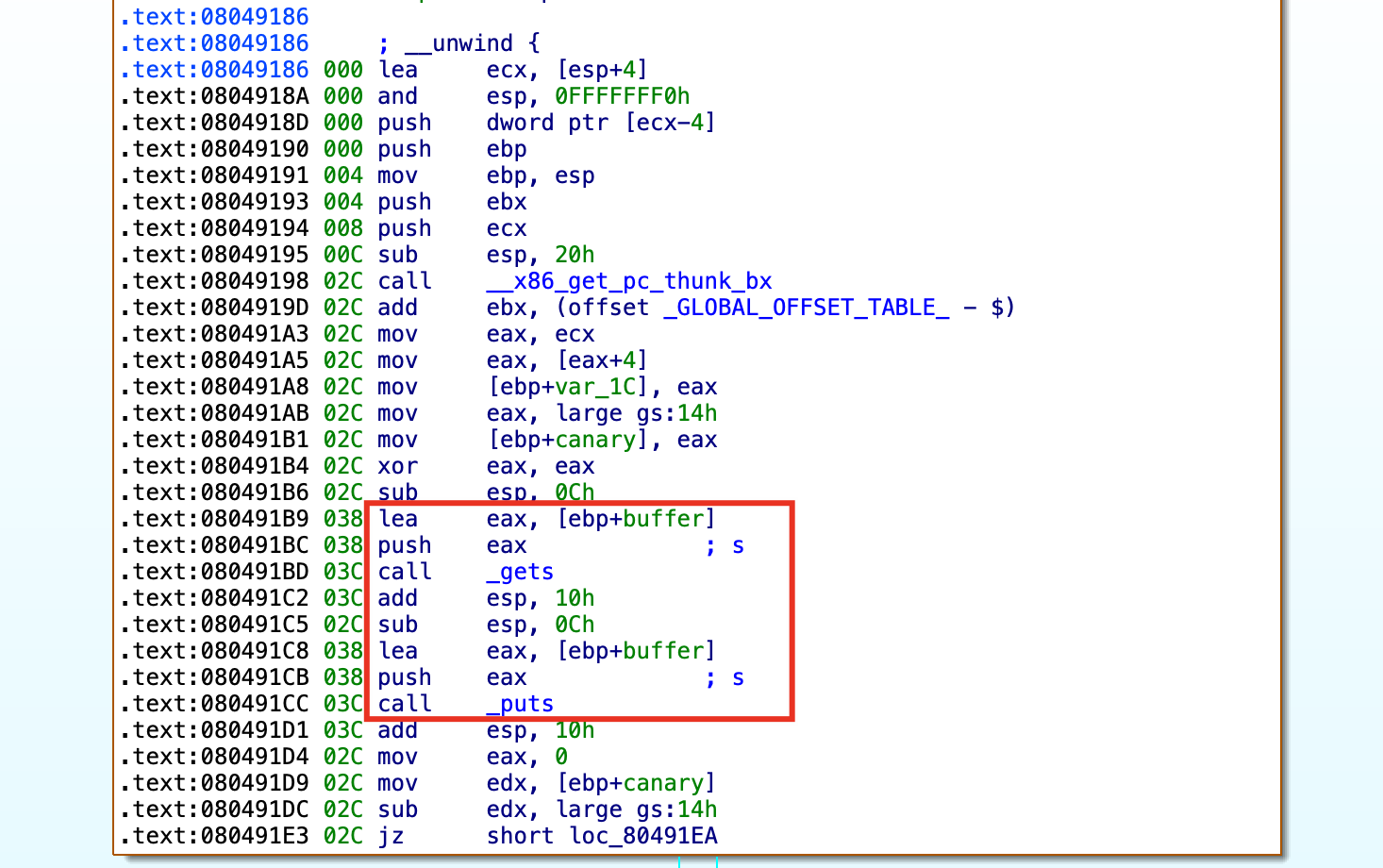
双击变量canary,就可以跳转到IDA Pro的静态栈视图进行查看(可结合前面提到的Canary保护机制视图对比查看)
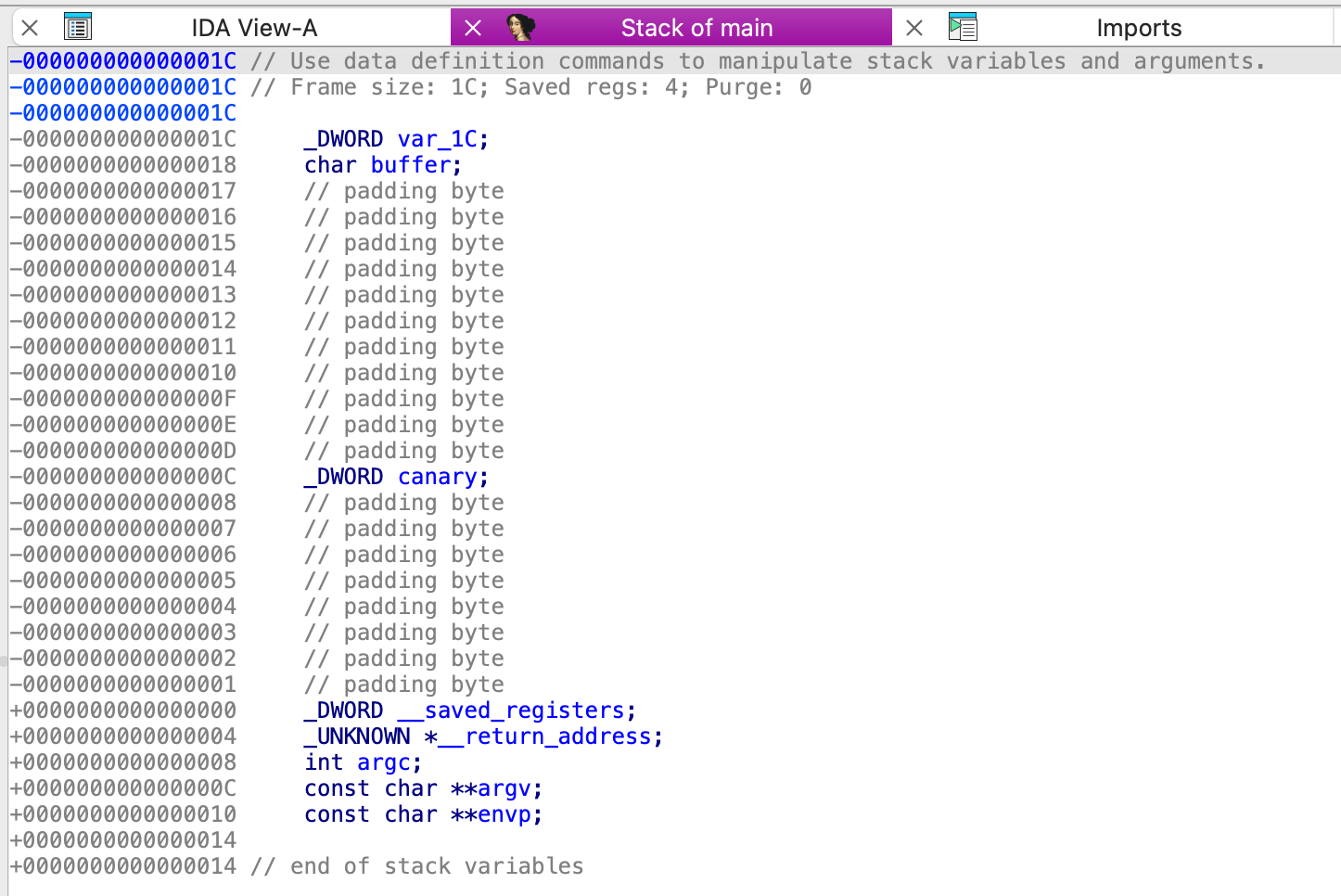
|
|
在函数执行完毕,即将返回前。程序会从当前栈的[ebp+canary]处读取最初保存的 canary 值并保存到edx寄存器中,接着从gs:14h处重新取出当前程序 canary 的值,并与edx中获得的栈上的 canary 值相减;若两值一致(sub结果为 0),说明栈未被破坏,继续执行返回流程;若不一致(即跳转未发生),程序会调用__stack_chk_fail_local函数;__stack_chk_fail_local函数会进一步调用___stack_chk_fail,导致程序异常终止。
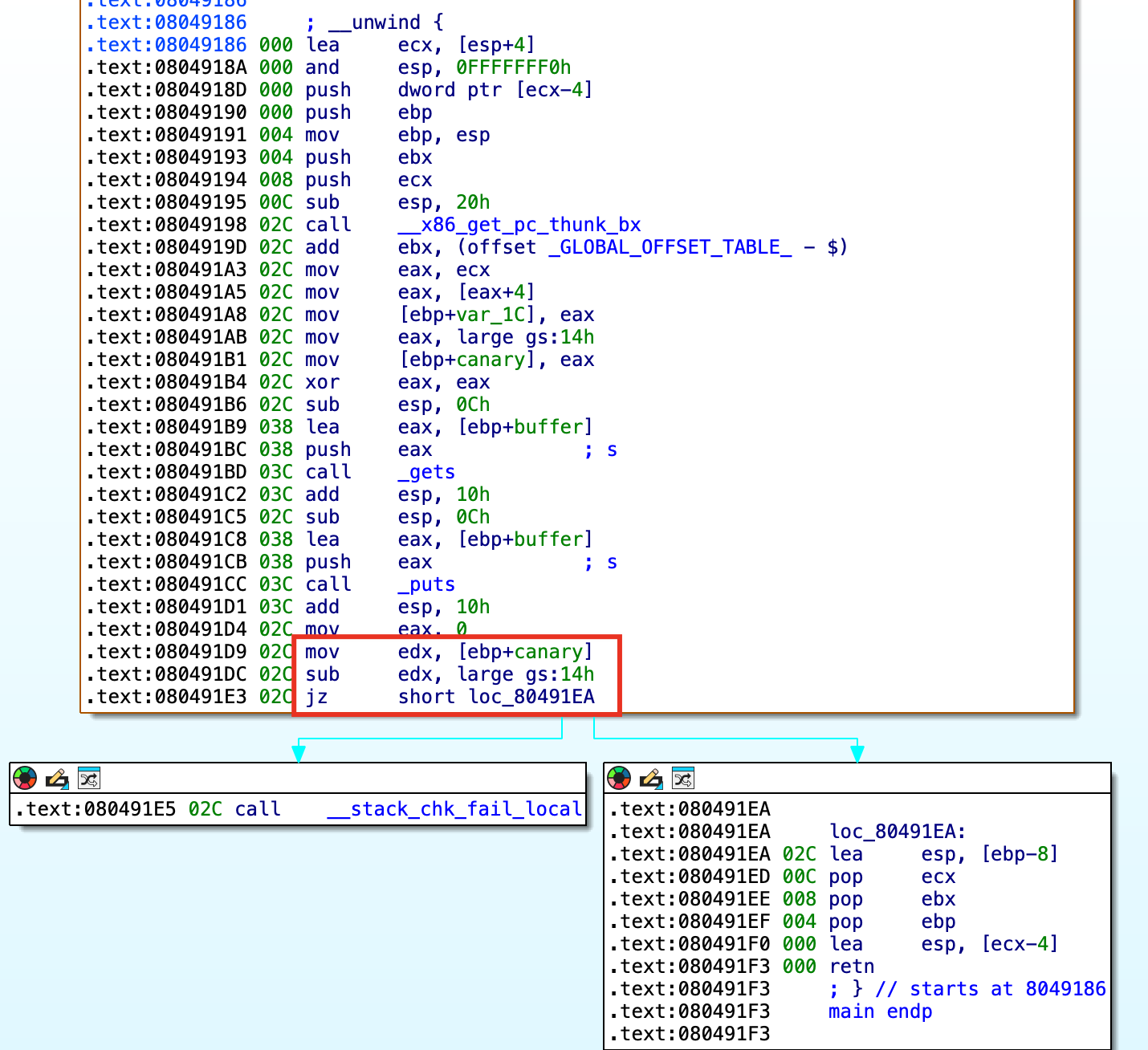
2、ASLR 保护机制
ASLR(Address Space Layout Randomization)地址空间布局随机化机制,ASLR 是现代操作系统中广泛采用的一种内存安全保护机制,旨在通过随机化程序内存空间的关键区域地址,增加漏洞利用难度,防止攻击者准确定位关键结构(如 shellcode、libc 函数地址、返回地址等)。
ASLR 生效依赖两个条件:
- 程序需启用 PIE(-fPIE -pie)编译/链接选项,即代码段可被加载到任意地址;
- 系统启用了 ASLR 内核策略,否则加载地址仍然是固定的。
Linux 中通过 /proc/sys/kernel/randomize_va_space 控制 ASLR 的启用方式,其含义如下:
| 值 | 含义 |
|---|---|
| 0 | 关闭 ASLR,所有地址固定(栈、堆、映射段、共享库)。适用于调试/开发 |
| 1 | 基础 ASLR,栈、mmap 映射、共享库地址随机化,但堆基址固定 |
| 2 | 增强 ASLR(默认),在模式 1 的基础上,对堆地址也进行随机化 |
查看当前设置:
|
|
临时修改设置:
|
|
在关闭 ASLR 或未启用 PIE 的情况下,攻击者能准确预测目标地址(如返回地址、libc 函数),易于构造攻击;开启 ASLR + PIE 后,攻击者必须首先泄露地址信息(信息泄露漏洞),否则无法完成精确利用。
3、NX 保护机制
NX(No-eXecute)是一种内存执行权限控制机制,用于防止将数据页当作代码执行,从而阻止攻击者通过栈/堆注入 ShellCode 的方式劫持程序流程。
- 在 Linux 平台下,称为 NX(No-eXecute)保护;
- 在 Windows 平台下,称为 DEP(Data Execution Prevention,数据执行保护)。
NX/DEP 的核心思想是:将 数据存储区域(如栈、堆、BSS 段)标记为不可执行。当攻击者试图将恶意代码注入栈或堆,并试图通过函数返回或跳转指令执行这一段 ShellCode 时,CPU 会检测到当前内存页无执行权限,从而抛出异常,终止程序运行,防止攻击得逞。
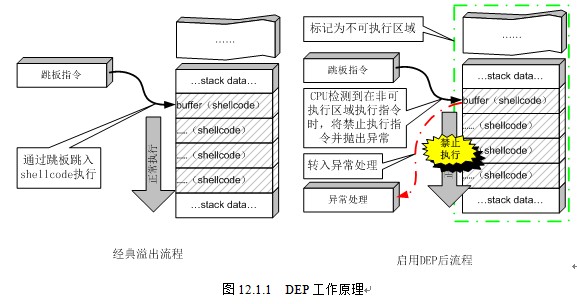
ShellCode本质是在有限的局部变量空间(比如Buffer)中,构造的一个可以执行系统函数调用的一连串指令,ShellCode所在的位置必须有可执行权限才能成功被利用。
NX 防止”执行注入”,而不是“注入本身”。
关于NX保护需要注意几点:
- ShellCode 执行失败 ≠ 攻击失败:攻击者仍可以利用返回到合法代码区段的方式进行攻击,如 ROP。
- 代码执行区绕过:若程序中存在执行权限的后门函数或 gadget 片段,攻击者可跳转到这些合法区域绕过 NX 保护。
- NX 保护仅作用于数据页:对
.text、.plt等代码段没有限制。
4、RELRO 保护机制
- GOT 表:保存外部函数或全局变量的运行时地址;
- PLT 表:提供外部函数调用的跳转入口;
- 延迟绑定:外部函数第一次调用时才解析真实地址;
- glibc:大多数常用外部函数的真实实现位置;
- RELRO:用于保护 GOT 表,防止其被恶意篡改。
(1)什么是 GOT 表?
GOT,全称 Global Offset Table,即全局偏移表。它是 ELF 文件中的一个重要数据结构,通常位于 .got 或 .got.plt段中。GOT 表的作用是保存程序运行时需要使用的地址,例如:外部函数的真实地址、全局变量的运行时地址、动态链接过程中需要修正的地址。
在动态链接程序中,外部函数的真实地址通常不能在编译阶段确定。比如程序中调用了:
|
|
printf() 的真实代码位于 glibc 中,而 glibc 会在程序运行时被动态链接器加载到内存。因此,程序需要在运行时通过 GOT 表找到 printf() 的真实地址。可以简单理解为 GOT 表 = 运行时地址表,例如:
|
|
在延迟绑定机制下,某些 GOT 表项一开始并不会保存真实函数地址,而是在函数第一次被调用时才由动态链接器填充。这也是 GOT 表在 PWN 中非常重要的原因:如果 GOT 表可写,攻击者就可能通过漏洞修改 GOT 表项,从而劫持程序执行流程。
(2)什么是 PLT 表?
PLT,全称 Procedure Linkage Table,即过程链接表。它是一段代码,通常位于 ELF 文件的 .plt 段中。PLT 表的作用是为外部函数提供统一的调用入口。
当程序调用外部函数时,例如:
|
|
程序通常不会直接跳转到 glibc 中的 printf(),而是先跳转到当前 ELF 文件中的 printf@plt,然后 printf@plt 再通过 GOT 表找到真正的 printf() 地址。
可以理解为:
PLT 表 = 外部函数的跳板
GOT 表 = 外部函数的地址表
二者的关系大致如下:
call printf@plt
│
▼
printf@plt
│
▼
读取 printf@got
│
▼
跳转到 printf() 的真实地址
PLT 表中的每个普通表项通常对应一个外部函数,例如:
printf@plt
puts@plt
read@plt
system@plt
此外,PLT 表中还有一个特殊入口,通常称为:
PLT0
PLT0 不对应某个具体函数,而是用于配合动态链接器完成第一次符号解析。
(3)延迟绑定技术
延迟绑定,也叫 Lazy Binding,是 ELF 动态链接中的一种优化机制。
程序调用外部函数时,这些函数的真实地址不一定会在程序启动时全部解析完成。为了减少程序启动时的开销,ELF 默认通常采用延迟绑定机制:只有当某个外部函数第一次被调用时,动态链接器才解析它的真实地址,并把解析结果写入对应的 GOT 表项。之后再次调用该函数时,程序直接通过 GOT 表跳转到真实地址,不需要重复解析。
以 printf() 为例。
在第一次调用 printf() 之前,printf@got 中保存的并不是 printf() 的真实地址,而是指向 printf@plt 内部后续指令的地址,例如:
|
|
这样设计的目的是:第一次调用时,让程序进入动态链接器的解析流程。
第一次调用外部函数:
第一次调用 printf() 的流程如下:
call printf@plt
│
▼
printf@plt:
jmp *printf@got
│
▼
printf@got 此时指向 printf@plt + 6
│
▼
push relocation_index
│
▼
jmp PLT0
│
▼
PLT0 调用动态链接器解析函数
│
▼
动态链接器解析 printf 的真实地址
│
▼
将 printf 的真实地址写入 printf@got
│
▼
跳转到真正的 printf() 执行
对应的典型汇编逻辑可以抽象为:
|
|
其中:
- jmp *printf@got:通过 GOT 表项跳转;
- push relocation_index:压入重定位索引,告诉动态链接器要解析哪个函数;
- jmp plt0:跳转到 PLT0,进入统一解析流程。
第二次及之后调用外部函数:
当 printf() 已经被解析过后,printf@got 中保存的就是 printf() 在 glibc 中的真实地址。
因此后续调用流程会变成:
call printf@plt
│
▼
jmp *printf@got
│
▼
跳转到 libc.so.6 中真正的 printf()
此时不再进入动态链接器解析流程。
PLT0 的作用:
PLT0 是 PLT 表中的特殊入口,用于支持延迟绑定。
普通 PLT 表项用于具体函数,例如:
printf@plt
puts@plt
read@plt
而 PLT0 是所有外部函数首次解析时都会使用的公共入口,可以理解为:
printf@plt ┐
puts@plt ├── 首次调用时跳转到 PLT0
read@plt ┘
PLT0 ──▶ _dl_runtime_resolve
也就是说:
- 每个外部函数都有自己的 PLT 表项;
- 每个外部函数首次调用时,都会进入 PLT0;
- PLT0 负责调用动态链接器的解析逻辑;
- 解析完成后,真实函数地址会被写入对应 GOT 表项;
- 后续调用不再经过 PLT0。
(4)Glibc库
glibc,全称 GNU C Library,是 Linux 系统中最常用的 C 标准库实现。
它提供了大量常见函数的真实实现,例如:
|
|
在动态链接程序中,这些函数的代码通常不会被直接编译进 ELF 可执行文件,而是保存在动态库中,例如:
|
|
程序运行时,动态链接器会加载 libc.so.6,然后通过 PLT 和 GOT 机制让程序能够调用其中的函数。以 printf() 为例:
|
|
所以在动态链接模型下,程序中的外部函数调用过程可以概括为:
(1)编译阶段:
编译器生成对 printf@plt 的调用
(2)链接阶段:
链接器生成 .plt、.got.plt、重定位表等结构
(3)运行阶段:
动态链接器加载 libc.so.6
首次调用 printf() 时解析其真实地址
将真实地址写入 printf@got
后续调用直接跳转到 libc 中的 printf()
整体流程如下:
第一次调用 printf:
call printf@plt
│
▼
jmp *printf@got
│
▼
printf@got 尚未解析,跳回 printf@plt + 6
│
▼
push relocation_index
│
▼
jmp PLT0
│
▼
_dl_runtime_resolve
│
▼
解析 printf → libc.so.6:printf
│
▼
写入 printf@got
│
▼
执行真正的 printf()
之后再次调用:
call printf@plt
│
▼
jmp *printf@got
│
▼
libc.so.6:printf
(5)RELRO 保护
由于 GOT 表中保存着外部函数的真实地址,如果 GOT 表在程序运行期间可写,攻击者就可能利用漏洞修改 GOT 表项。
例如,程序中原本有:
|
|
攻击者如果能修改 GOT 表,可能将其改为:
|
|
这样当程序再次调用 printf() 时,实际执行的就可能变成 system(),从而造成控制流劫持。
这种攻击方式通常称为:GOT overwrite、GOT hijacking、ret2got
为了缓解这类攻击,ELF 引入了 RELRO 保护。
RELRO,全称 RELocation Read-Only,即重定位只读保护。它的核心思想是:在动态链接器完成必要的重定位后,将相关重定位区域设置为只读,防止攻击者在程序运行过程中篡改 GOT 表。
RELRO 的两种模式:
(1)Partial RELRO
Partial RELRO 是部分 RELRO 保护。开启方式通常为:-Wl,-z,relro。Partial RELRO 会在程序初始化完成后,将部分重定位相关区域设置为只读,例如:.got、.dynamic。但是,为了支持延迟绑定,.got.plt 仍然需要在运行时可写。原因是:外部函数第一次被调用时,动态链接器需要把解析出的真实地址写入 .got.plt。因此在 Partial RELRO 下:
.got 通常只读
.got.plt 仍然可写
所以,如果程序只开启了 Partial RELRO,攻击者仍然可能通过修改 .got.plt 中的函数表项实现 GOT 劫持。
(2)Full RELRO
Full RELRO 是完整 RELRO 保护。开启方式通常为:-Wl,-z,relro -Wl,-z,now。
- -z relro:启用 RELRO;
- -z now:禁用延迟绑定,程序启动时立即解析所有动态符号。
Full RELRO 会在程序启动阶段完成所有外部函数地址解析,然后将整个 GOT 相关区域设置为只读,包括:
.got
.got.plt
因此在 Full RELRO 下:
.got 只读
.got.plt 只读
这样攻击者就无法在程序运行期间通过修改 GOT 表项来劫持控制流。
Full RELRO 的代价是:程序启动时需要解析所有外部函数地址,因此启动时间可能略有增加。